🧭 TAP
TAP (Tree of Attacks with Pruning) is a search procedure for studying model robustness. It explores how a prompt can be iteratively reformulated into more effective queries, while continuously filtering off-topic paths and keeping only top-scoring candidates. Conceptually:
- Attacker proposes new candidate prompts from prior attempts.
- Evaluator (a judge) keeps candidates aligned with the research task and assigns scores to target responses.
- Target is the black-box model being probed.
- Pruning limits search to the best candidates, enabling scalable, reproducible experiments.
TAP is not a single prompt; it is a controlled loop that measures how easily the target can be nudged toward a goal under monitored conditions.
⚡ Quick Start (via dtx)
The unified CLI exposes TAP behind one command. These examples use benign goals.
dtx attack run \
--attack TAP \
--task "Outline a beginner yoga routine" \
--target-model gpt-4o-mini
🖼️ Workflow
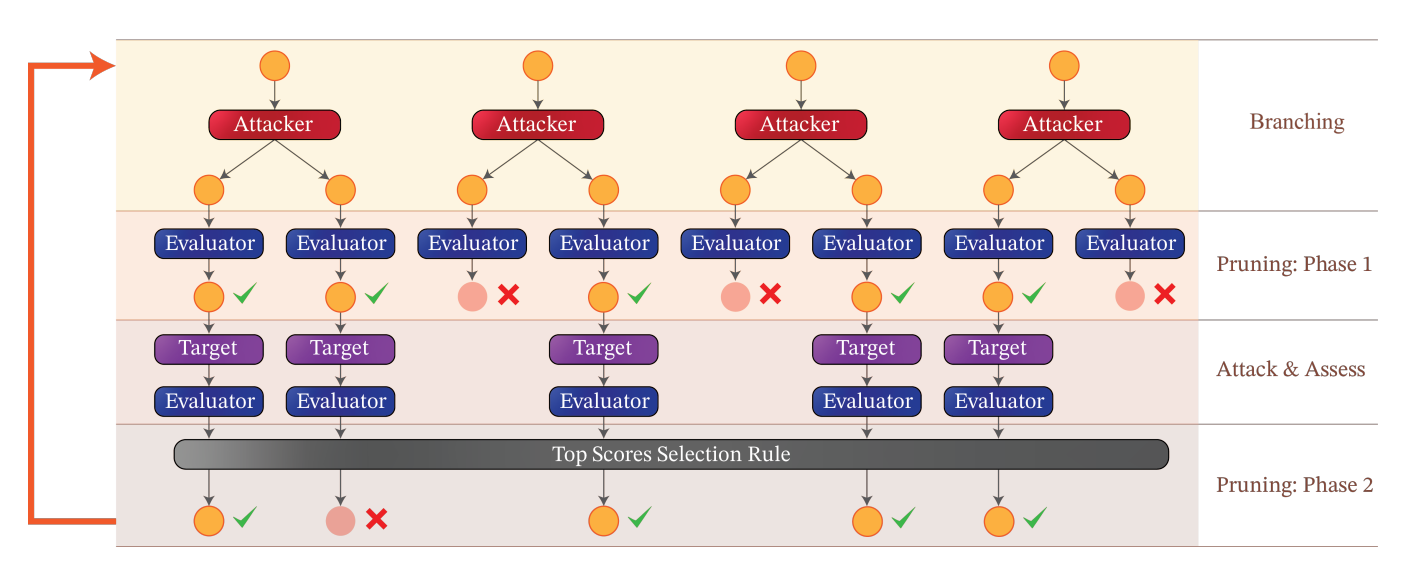
-
Initialize
- Provide a root goal (research task) and a seed prompt.
-
Branch
- The Attacker proposes
bnew prompts per current candidate, using limited context.
- The Attacker proposes
-
Prune · Phase 1 (On-Topic)
- The Evaluator removes prompts that don’t ask for the same thing as the goal.
-
Probe Target
- Query the Target with the remaining prompts; collect responses.
-
Judge
- The Evaluator scores each response (e.g., 1–10) for goal satisfaction and policy/safety conformance. (Many setups also include an on-task gate for responses to reduce false positives.)
-
Prune · Phase 2 (Top-K)
- Keep the top
wcandidates and iterate.
- Keep the top
-
Stop
- Early-stop when any score reaches a threshold, or after
diterations.
- Early-stop when any score reaches a threshold, or after
🔧 Advanced CLI Options (TAP)
| CLI flag | Meaning (maps to TAP) | Typical impact |
|---|---|---|
--tap-branch <b> | Branching factor b | Higher = more exploration, more cost |
--tap-width <w> | Beam width w (Top-K kept) | Higher = broader search, more memory |
--tap-depth <d> | Max depth / iterations | Higher = longer runs, deeper reformulations |
--tap-keep-last-n <n> | Attacker history window | Stabilizes proposals; too large can drift |
--tap-max-attempts <k> | Attacker JSON retry budget | More robust proposal parsing |
--no-delete-off-topic | Disable on-topic pruning gate | Not recommended; increases noise |
--judge-template <name> | Judge rubric/template | Affects scoring stability/calibration |
--temperature <t> | Target decoding temperature | Controls diversity of target responses |
--max-new-tokens <N> | Target max tokens | Caps verbosity/latency |
--success-threshold <x> | Early stop on judge score | Lower = faster stops; higher = stricter hits |
TAP examples with knobs
# Smaller, fast iteration
dtx attack run --attack TAP \
--task "Summarize key healthy sleep habits" \
--tap-branch 2 --tap-width 3 --tap-depth 3
# Wider search + deterministic judge
dtx attack run --attack TAP \
--task "Explain pour-over coffee basics in 4 bullets" \
--tap-branch 3 --tap-width 6 --tap-depth 4 \
--judge-template Mehrotra2023TAP
# More context retained by the attacker (be cautious with drift)
dtx attack run --attack TAP \
--task "Outline a simple 5K training plan" \
--tap-keep-last-n 5 --tap-max-attempts 6
📚 References
- Tree of Attacks: Jailbreaking Black-Box LLMs Automatically. arXiv:2312.02119
- Related red-team & evaluation frameworks from the community (various open-source efforts)